Ubuntu15.10系统安装Hadoop1.2.1集群
最近BigData貌似很火,本人也跟着一起凑凑热闹,尝试了本机部署Hadoop1.2.1版本,基于Hadoop1.2.1 + Python2.7 + Ubuntu15.10技术栈,讲述Hadoop集群的安装过程,有什么不准确之处可以留言,一起交流share。
1、摘要
由于Ubuntu对于Python的支持很好,个人也觉得Ubuntu确实不错,所以使用的是Ubuntu15.10系统,处理大数据采用Python + Hadoop的方式进行处理。
2、版本信息
| name | vsersion | remark |
|---|---|---|
| Ubuntu | 15.10 | 系统的版本 |
| Python | 2.7 | 开发语言 |
| JDK | 1.7 | Hadoop运行的基础环境 |
| Hadoop | 1.2.1 | 大数据处理工具 |
| VMware | 6.0 | 虚拟机 |
3、正文
本文主要讲述hadoop集群的安装过程,尽量依次按步骤执行。
3.1、虚拟机安装
首先VMware上安装4台虚拟机,分别是Ubuntu15.10系统,具体安装百度即可so easy。安装时候对电脑的机器名直接命名为master,node01,node02,node03(1个主节点,3个子节点),接下来2-7的操作是针对于这4台虚拟机分别进行同样的操作。
3.2、创建hadoop用户组
命令:sudo addgroup hadoop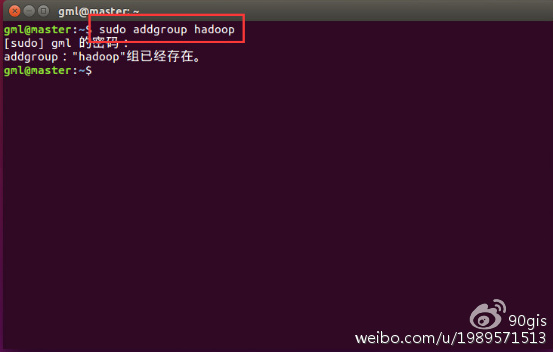
3.3、创建hadoop用户
命令:sudo adduser -ingroup hadoop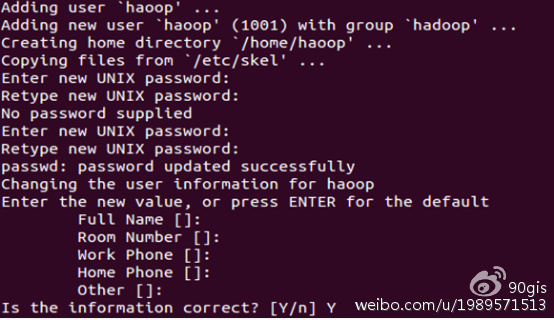
回车后会提示输入新的UNIX密码,这是新建用户hadoop的密码,输入回车即可。如果不输入密码,回车后会重新提示输入密码,即密码不能为空。最后确认信息是否正确,如果没问题,输入 Y,回车即可。
3.4、添加hadoop root权限
命令:sudo gedit /etc/sudoers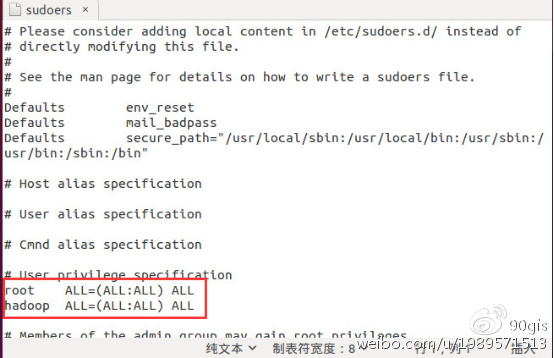
打开sudoers 文件,在root ALL=(ALL:ALL) ALL这行下面添加:
hadoop ALL=(ALL:ALL) ALL
修改完保存关闭即可。
** 注:如果系统的gedit用不了,自行上网解决,这里给出的方案是用vi或vim。**
3.5、切换到hadoop用户
命令:su hadoop,输入密码即可登录hadoop用户。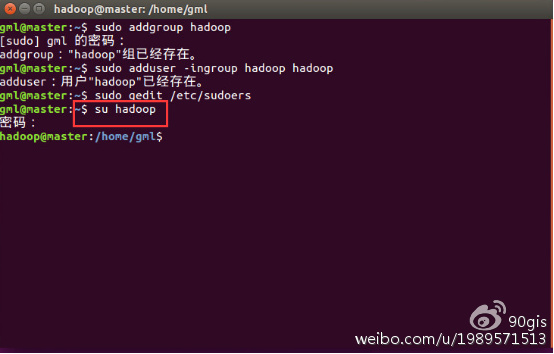
3.6、安装ssh
命令:sudo apt-get install openssh-server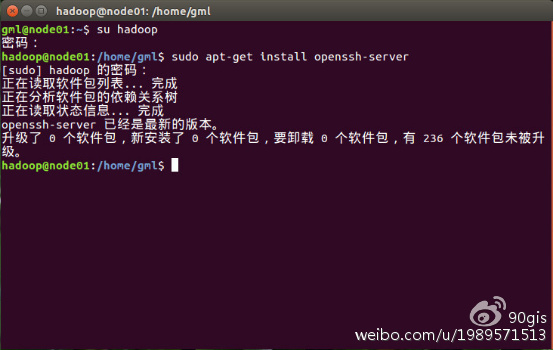
安装完成后启动ssh服务,命令:sudo /etc/init.d/ssh start
查看ssh服务是否启动,命令:ps -ef | grep ssh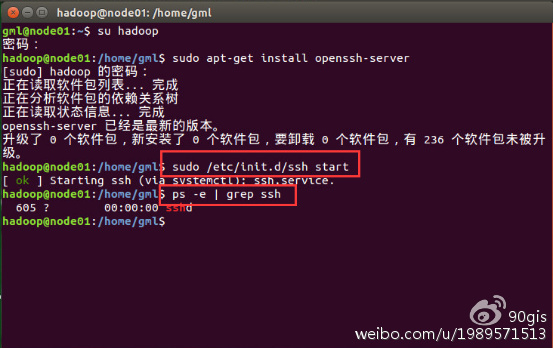
服务存在之后,设置实现ssh免密码登录,命令:ssh-keygen -t rsa -P “”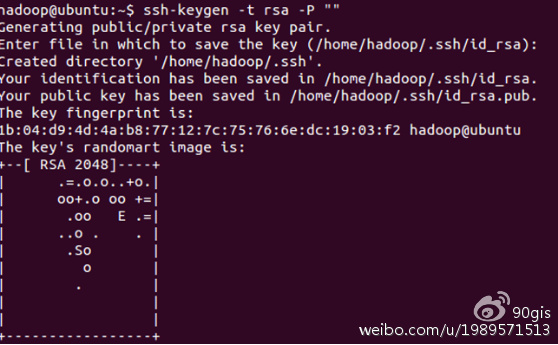
下面我们将公钥追加到authorized_keys中,它用户保存所有允许以当前用户身份登录到ssh客户端用户的公钥内容,命令:
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
3.7、登录ssh
命令:ssh localhost,退出,命令:exit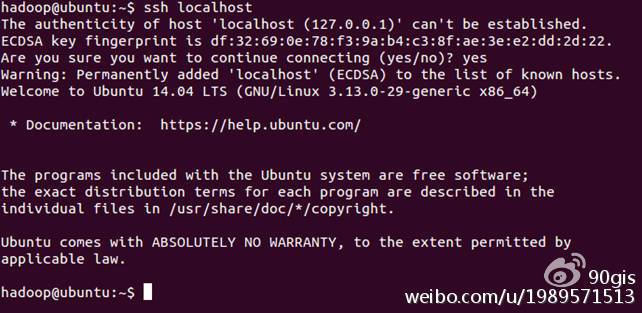
3.8、安装Java环境
命令:sudo apt-get install openjdk-7-jdk
查看安装结果,输入命令:java -version,结果如下表示安装成功。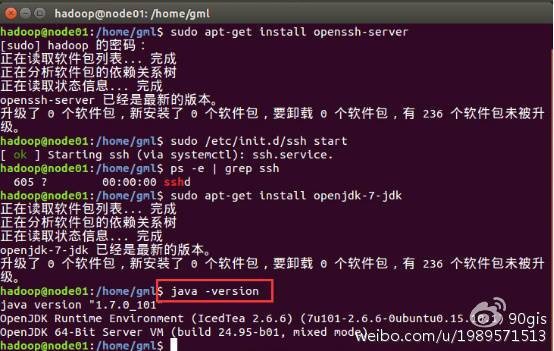
注:java安装默认路径:/usr/lib/jvm/java-7-openjdk-amd64
以上操作基于hadoop用户,并且每个电脑配置一致
3.9、hadoop配置
正餐开始了,仔细看!!!
3.9.1、hadoop-env配置:
进入到hadoop文件的conf文件夹,使用命令:sudo gedit hadoop-env.sh
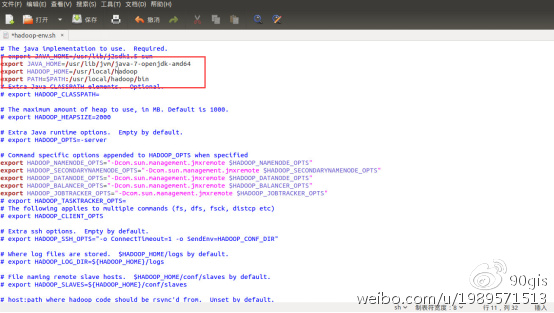
添加以下信息到文件中,保存即可。
解释下内容:JAVA_HOME是java的安装路径,HADOOP_INSTALL是hadoop的安装路径,PATH是系统文件路径:
1 | |
1 | |
1 | |
1 | |
3.9.5、master和slaves配置
hadoop文件的conf文件夹,使用命令:sudo gedit master,sudo gedit slaves
在master文件中添加主节点计算机名称/IP即可。
在slaves文件中添加子节点计算机名称/IP即可。
3.10、复制hadoop
把hadoop分别向其他机器上复制一份,放到相同目录。
命令:scp(自行百度用法,这里不做详述)
3.11、建立hadoop所需文件夹
在每个机器上建立所需要的文件夹,在步骤8中有core中配置的hadoop.tmp.dir文件夹,hdfs中配置的dfs.data.dir文件夹,需要进行建立以及是hadoop用户,读写权限。
执行命令:sudo mkdir
3.12、格式化namenode
进入到hadoop/bin目录,在主节点机器上执行命令:hadooop namenode -fomat,出现successfully字样成功,不成功大部分都是配置文件的问题。
3.13、启动hadoop
在主节点机器上进入hadoop/bin目录下,执行命令:hadoop-start.sh,分别会启动NameNode,Jobtracker,SecondaryNameNode,DataNodeTaskTracker
3.14、查看hadoop
在主节点机器上执行命令:jps,在主节点机器上会出现以下进程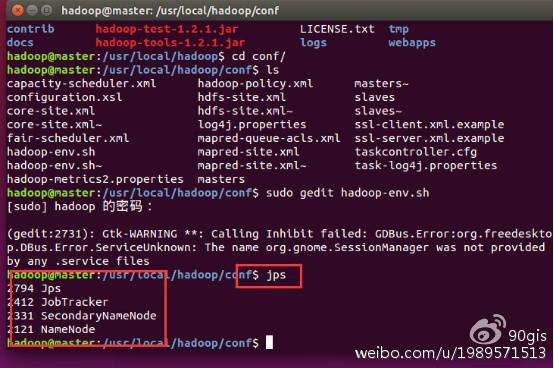
在子节点机器上执行命令:jps,在子节点机器上会出现以下进程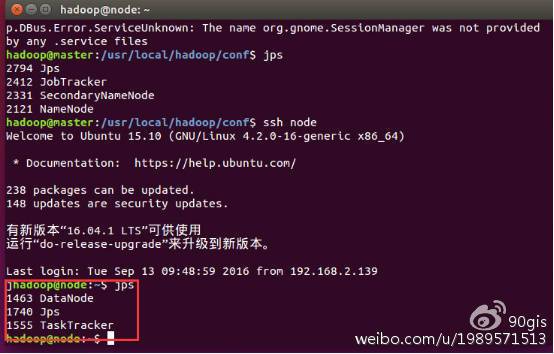
3.15、查看运行状态
在浏览器中输入主机IP:50030,会出现hadoop运行状态。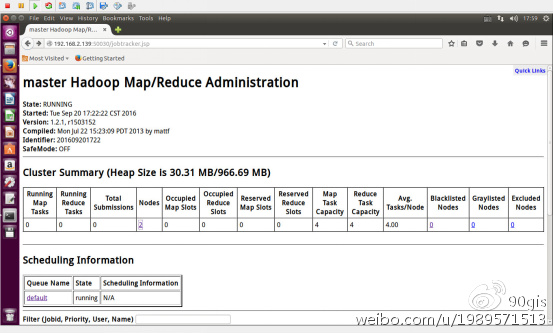
3.16、停止hadoop
在主节点机器上进入到hadoop/bin目录下,执行命令:stop-all.sh,这样hadoop停止运行。
4、建议
程序这个东西就得多实践,不去写、不去运营,永远不知道会发生什么bug,本人也初学,有不对的希望大家谅解。